 Audio Transcription
Audio Transcription Datasets and Services for Training LLM
Datasets and Services for Training LLM Image Annotation
Image Annotation Video Annotation
Video Annotation Text Annotation
Text Annotation Lidar Annotation
Lidar Annotation Crowdsourcing
Crowdsourcing MedTech Companies
MedTech Companies Banking and Finance Industry
Banking and Finance Industry Biometric Data
Biometric Data E-commerce and Retail
E-commerce and Retail Surveys and UX-Researches
Surveys and UX-Researches Agriculture
Agriculture Retail
Retail Robotics
Robotics Augmented Reality
Augmented Reality Finance
Finance E-Commerce
E-Commerce Face Recognition System
Face Recognition System Ore Annotation
Ore Annotation Content Moderation on the Video
Content Moderation on the Video IBeta 2
IBeta 2 Data Collection for Face and Speech Recognition
Data Collection for Face and Speech Recognition Content Moderation
Content Moderation Video Systems and Video Analysis
Video Systems and Video Analysis Content Moderation in Recruitment Domain
Content Moderation in Recruitment Domain Audio Labeling for Call Center
Audio Labeling for Call Center Data collection and video annotation: weapon detection on the streets
Data collection and video annotation: weapon detection on the streets Image Annotation for Emotion Recognition
Image Annotation for Emotion Recognition Data Сollection for Сity Administration
Data Сollection for Сity Administration Liveness Detection
Liveness Detection Annotation Photos for the Recognition System
Annotation Photos for the Recognition System Blog
Blog Stages of Work
Stages of Work Become a Partner
Become a Partner Student Program
Student Program FAQ
FAQAutomated data labeling: everything you need to know
What is automated data labeling
Automated data labeling is the process of training a model on a limited labeled dataset which is later used for labeling new sets of data. Over time, the model is trained on more and more data hence helping it achieve higher levels of accuracy in contrast to manually labeled data.
Automating this process has revolutionized the analysis of larger volumes for businesses.
It has significantly reduced the need for machine learning specialists to manually label large datasets.
Automating labeling has accelerated the time needed to create an AI product, as data collecting and labeling is the most tedious task in any project. Besides the time reduction, automation helps achieve more accurate results minimizing any possible human errors.
There are numerous real-life applications for that, below we have introduced some of the most common ones:
| Image recognition | e.g. to identify people, objects, and other existing elements on an image |
| Sentiment analysis | e.g. to analyse customer or user feedback and help single out insights on user preferences |
| Speech recognition | e.g. to transcribe speech to text and help businesses analyze user interactions and identify areas for improvement |
Automated data labeling helps businesses get more informative insights into how the product or service performs and identify patterns to make realistic data-driven decisions. Labeling automation should come before implementing any kind of AI-driven chatbots or AI assistants, as it gives you a quick transformation of your raw data into structured and actionable insights.
Having your data labeled will help your other business automation initiatives run smoother, upscaling the efficiency.
Manual vs automated labeling
Manual labeling is when human reviewers analyze every entry point, identify the context and label accordingly. It is a time-consuming process and can contain numerous errors. Moreover, the process can undergo human bias resulting in inconsistency and reduction in quality.
There are certain scenarios, however, where manual input is a better option. For instance, human reviewers are better suited to work with subjective cases like sentiment detection or cultural phenomena where automation algorithms can fail to come up with accurate judgments.
Additionally, choosing manual method over automation can be a wiser option when working on a small dataset, which doesn’t justify the costs to be spent on automation.
Automated data labeling, on the contrary, operates on a trained machine-learning algorithm that assigns labels to chosen data points. This algorithm-driven labeling is quicker and more accurate, free of human errors. This can help reduce manual labor and eliminate any human bias.
However ideal automated data labeling may sound, it also comes with challenges to consider. The accuracy greatly depends on the complexity of assigned tasks and the quality of training data. Moreover, some data points with complex elements or contextual meaning such as humor or sarcasm can be challenging to label with automation.
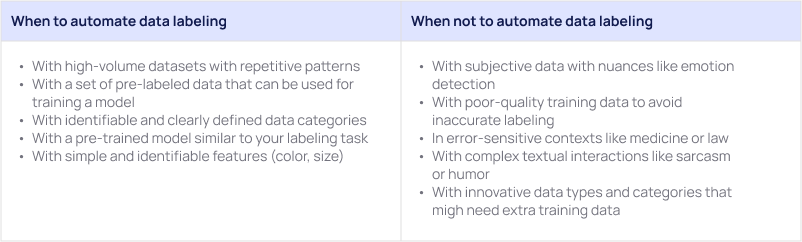
When can you choose automated data labeling?
The choice between manual and automated data labeling entirely depends on your project needs and budget. But here we have compiled a list of cases where it is better to choose automation:
- If you have high-volume datasets with repetitive patterns like object recognition on an image within the same context.
- If you have a set of pre-labeled data that can be used for training a model to auto-label similar data.
- If you have identifiable and clearly defined data categories with no need for human interpretation.
- If you have a pre-trained model that is closely associated with your task, you can fine-tune the existing ML model (transfer-learning) based on your needs.
- If your task requires simple and identifiable features to label like color, presence of objects, size etc.
When can you not automate?
There are some cases when you cannot or at least shouldn’t automate your tasks. Most commonly it is not useful to automate data labeling when dealing with complex and subjective data, you better refrain from automation. Here are some cases where automation is not the best choice:
- If you have subjective tasks with nuances bound for human interpretation like analysis of emotions and sentiments, cultural phenomena etc.
- If you have poor-quality training data which can result in nonefficient model performance with inaccurate labels
- If any minor labeling errors can lead to serious consequences. For example in medical and legal contexts, where only automated labeling might produce inappropriately labeled data.
- If you have complex textual interactions or not easily identifiable images.
- If you have new innovative categories that haven’t been previously used to train existing models.
Automation process and techniques
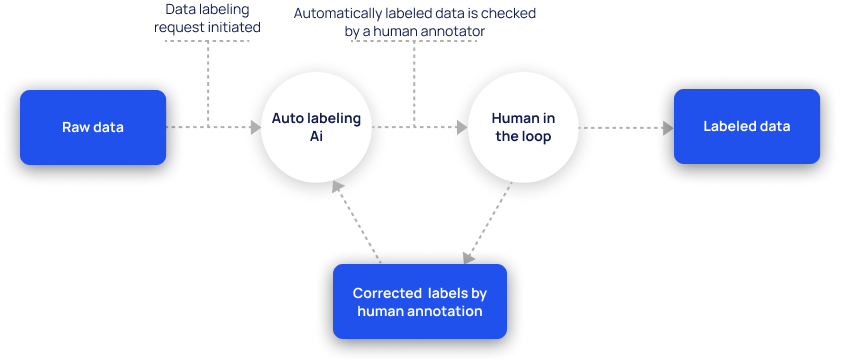
Automated data labeling uses algorithms and machine learning techniques to automatically annotate data. Here is a step-by-step explanation of the automation process:
1. Choose the initial data
In the initial stage of automation, you will need to select a small dataset that has been labeled manually. You will use this as the model training foundation, to provide the system with correct labels.
2. Select a suitable technique
Various machine-learning techniques are designed to learn from your initial data to predict new labels for new sets of unlabeled data. Some of the most common techniques are:
- Supervised learning – learns how to label on previously labeled datasets and consists of input and output labels. This is commonly used for speech recognition, NLP and image recognition.
- Unsupervised learning – uses a clustering algorithm to group similar end points and predicts patterns without any pre-labeled data. This can be used for customer segmentation and recommendation generators.
- Deep learning – uses neural networks composed of layered nodes and can learn to identify complex features from raw data and output them into such labels as reasons and topics.
3. Refine the automation process with active listening
Active listening helps the system flag those labels that are with low confidence so that you refine them manually. You can later add those manually labeled data to the training set to further improve the uncertain predictions.
4. Upscale and improve labels
Over time, as the task volumes increase, the system becomes more accurate. You can therefore continuously improve and fine-tune the model to help handle broader ranges of data and more complex tasks.
5. Check for quality and stay in the loop
Even though the process is quite independent, it still needs human supervision to remain accurate. You will need to periodically check the systems to control accuracy, especially with unique cases.
Tools
There are various tools used in machine learning developed to automate the data labeling process, thereby enhancing efficiency, accuracy, and scalability. Here are 3 of the most notable automation tools:
- Amazon SageMaker Ground Truth: It offers such features such as pre-built workflows and integrated machine learning to reduce the time, effort, and cost of labeling your data. It supports various input types, including images, text, and 3D point clouds, making it versatile for different ML projects.
- Labelbox։ Features include a user-friendly interface, collaboration tools for teams, and the ability to train and improve your own machine learning models to automate the annotation process. Labelbox supports a diverse range of data types and annotation tasks, making it suitable for projects in industries like agriculture, autonomous vehicles, and healthcare.
- Snorkel AI։ Instead of manually labeling each piece of data, Snorkel AI allows users to write functions that automatically label the task based on heuristics, patterns, or other characteristics identified by the user. Snorkel is particularly useful for projects where acquiring large amounts of hand-labeled data is impractical or too expensive.
Benefits and limitations
Automated data labeling has become increasingly relevant in the field of machine learning and due to its promise of reducing the labor-intensive and time-consuming process of manual data annotation. But what are the benefits and limitations? Let’s see the most common ones.
Benefits
- Cost reduction: Automation helps reduce the need for human annotation and significantly lowers model training preparation costs.
- Consistency: Trained algorithms can apply similar criteria across vast datasets hence minimizing subjectivity and inconsistency that can come with manual annotations.
- Efficiency and scalability: Due to its ability to deal with larger volumes of data at a time in contrast to human input, it saves time and allows scaling the project in short periods.
- Agility: With auto-labeling, you can perform iterative sprints by adding new small classes at a time by making the changes manageable.
Limitations
- Dependency of use cases: Before choosing to use automation, you need to precisely evaluate your domain, data type and context so that you can properly train the model.
- Area of application: This method is helpful only with noncomplicated inputs with traditional categories.
- Algorithm quality: The quality of labels is directly reliant on the quality of the training model and the appropriateness of the model to the specific task.
- Edge cases: Automation can not deal with ambiguity and cases that don’t fit into universal categories, leading to inaccuracies.
Common use cases
Data labeling automation is used in numerous cases across industries where machine learning is applicable. We have listed some of the most common areas of application:
- Retail and e-commerce: Retail and e-commerce industries typically need automation for quicker product categorizations, catalog management, and customer sentiment detections to enhance search recommendations. Read through a real-life use case of using annotation for sentiment analysis in e-commerce case study by our team at Training data.
- Agriculture: Labeling can be used for aerial imagery or drone footage to label crop health, predicting drought impacts and monitor livestock health, behaviour and headcount.
- Autonomous vehicles: Automated labeling of road features, traffic signs, and pedestrian info in imagery to train autonomous driving systems.
- Security and surveillance: Security services can use this to detect unusual behaviors or items in surveillance footage to flag potential security threats or safety violations.
- Environmental monitoring: Analyzing satellite imagery to label different land use types, such as forests, urban areas, and water bodies, for environmental monitoring and planning.
- Natural language processing (NLP): Automatically labeling texts (reviews, social media posts) to indicate sentiment (positive, neutral, negative), valuable for market research and customer feedback analysis.
In sum
Automated data labeling has been a game changin advancement in preparing datasets for machine learning and AI development. It offers of mix of efficiency, scalability, and cost-effectiveness unmatched by manual annotation methods.
While limitations like accuracy and adaptability remain, the integration of human oversight and innovative machine learning techniques, like active learning, provide a balanced approach to achieving high-quality labeled data.
As technology progresses, the applications of automated labeling continue to expand across domains, making it an indispensable tool in the AI toolkit. Embracing automation is not just about enhancing productivity; it’s a strategic investment in the future of AI-driven innovation.
If you are considering automating your data labeling, contact us to discuss your needs and come up with suitable automation techniques.
FAQs
- How does automated data labeling ensure the accuracy of labels?
It uses machine learning algorithms to predict labels for unlabeled data based on patterns learned from an initial, manually labeled dataset. These systems use active listening, human-in-the-loop, and quality checks to ensure accuracy.
- Can automated data labeling handle all types of data?
It depends on the complexity of the dataset. Simple and well-defined tasks, such as identifying objects in images where the objects are clearly visible, are well-suited for automation. However, the datasets that require unique categorization and human validation to eliminate ambiguity are better handled with manual labour.
- What types of data can be labeled automatically?
Automated data labeling can be applied to various types of data, including images, videos, text, and audio. The effectiveness of automation tools may vary depending on the complexity of the task and the specificity of the labels.
