 Audio Transcription
Audio Transcription Datasets and Services for Training LLM
Datasets and Services for Training LLM Image Annotation
Image Annotation Video Annotation
Video Annotation Text Annotation
Text Annotation Lidar Annotation
Lidar Annotation Crowdsourcing
Crowdsourcing MedTech Companies
MedTech Companies Banking and Finance Industry
Banking and Finance Industry Biometric Data
Biometric Data E-commerce and Retail
E-commerce and Retail Surveys and UX-Researches
Surveys and UX-Researches Agriculture
Agriculture Retail
Retail Robotics
Robotics Augmented Reality
Augmented Reality Finance
Finance E-Commerce
E-Commerce Face Recognition System
Face Recognition System Ore Annotation
Ore Annotation Content Moderation on the Video
Content Moderation on the Video IBeta 2
IBeta 2 Data Collection for Face and Speech Recognition
Data Collection for Face and Speech Recognition Content Moderation
Content Moderation Video Systems and Video Analysis
Video Systems and Video Analysis Content Moderation in Recruitment Domain
Content Moderation in Recruitment Domain Audio Labeling for Call Center
Audio Labeling for Call Center Data collection and video annotation: weapon detection on the streets
Data collection and video annotation: weapon detection on the streets Image Annotation for Emotion Recognition
Image Annotation for Emotion Recognition Data Сollection for Сity Administration
Data Сollection for Сity Administration Liveness Detection
Liveness Detection Annotation Photos for the Recognition System
Annotation Photos for the Recognition System Blog
Blog Stages of Work
Stages of Work Become a Partner
Become a Partner Student Program
Student Program FAQ
FAQ
Licensed dataset
Anti-Spoofing Print Attack Dataset
Attacks with printed selfies of people. The dataset solves security tasks for biometric identification systems

- Liveness detection
- Facial Recognition
- Anti-Spoofing
- iBeta
4 700+
video
20
countries
5 days
from signing a contract
Our Partners








CASE DESCRIPTION
- Print attacks on selfie photos from Anti-Spoofing Real
- The dataset includes printers and backgrounds used for attack
- Each printed selfie from Anti-Spoofing Real is filmed on the smartphone camera with zooming
Technical specification
- Each set includes person's ID from Anti-Spoofing Real, video resolution, duration and frames per second
- The print attack duration varies from 10 to 20 seconds wth person's face in the center of the attack
- The camera distance from 2 to 0.2 meters for each attack
- Agreement when providing data for each person
- The dataset meets the requirements of ISO 30107-3 for Presentation Attack
- Type of attacks according to the biometric standard FIDO - Displayed videos on mobile devices, Level A
- Data allows you to reduce Attack Presentation Classificaiton Error Rate


-
Anti-Spoofing Real Unique
- Selfie photos and videos from Anti-Spoofing Real, every person in the dataset is unique
- Workers are identified as unique after the verification done by 3 individuals independently
- 38 000 sets with unique people
- Metadata from Anti-Spoofing Real
- Data in 3 days from signing the contract

-
Anti-Spoofing Real
- 98 000+ photos and videos where people turn their heads
- People from 170 countries
- The dataset complies with the requirements of ISO 30107-3 for Bona Fide Presentation
Read more
-
Anti-Spoofing Print
- 30 000+ videos of phone's displays with Real videos of a person
- Videos for replay attacks are taken from Anti-spoofing Real dataset
- The dataset complies with the requirements of ISO 30107-3 for Presentation Attack
- Type of the attack - Displayed videos on mobile devices, Level B (FIDO biometric standard)
Read more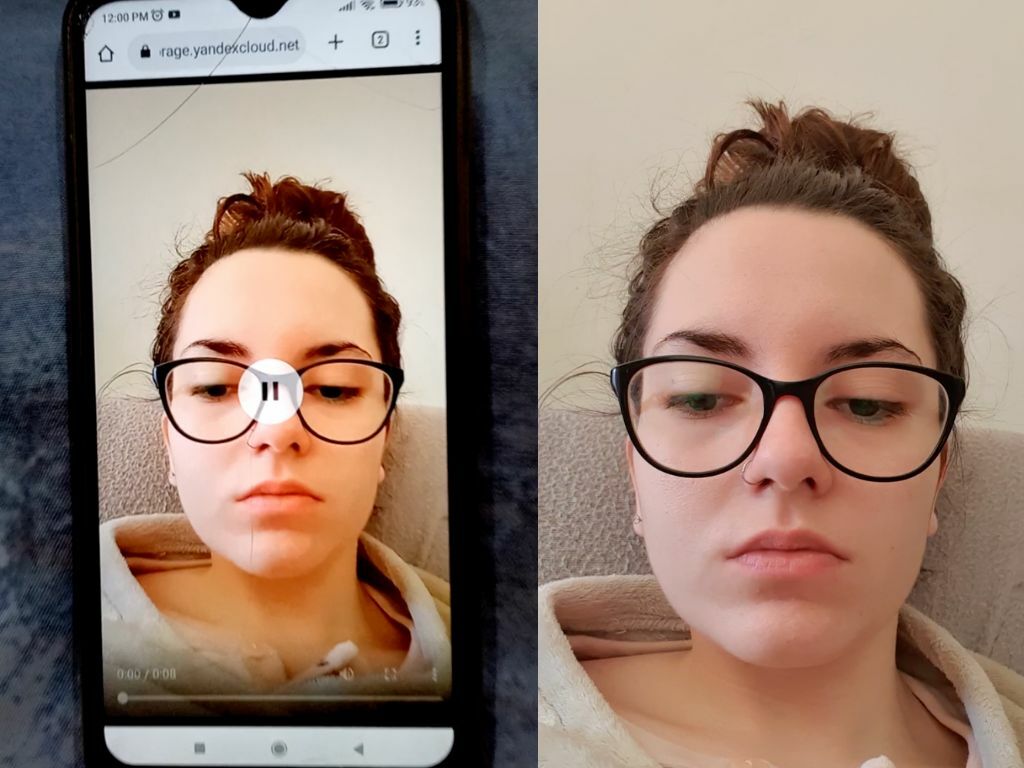
APPLICATION AREAS OF THE DATASET
Facial Recognition:
Data in the dataset to develop and assess facial recognition algorithms, enhancing security systems, unlocking devices, and verifying identity
Biometric Identification:
Computer vision to detect and authenticate individuals based on their unique physical characteristics, enabling secure access control systems
Anti-spoofing:
Data in the dataset to train the system to detect a real person in a video
How it works?
Once you submit a request, we will contact you to discuss the details and sign the necessary documents. When the documents are signed, you will have the data within 5 days.
How is the data collected?
We obtain data from both crowdsourcing platforms and our in-house team. The data is further validated by our in-house team.
Is it possible to get a part of the data?
Upon your request, we can provide part data for any datasets. If you have an interest in specific demographic characteristics, we offer parts from several datasets according to your needs.
Do you provide additional labeling for the dataset?
We offer additional labeling for an extra fee. For the dataset, we provide special ethnicity classification, lighting classification and other labeling according to your needs.
What is the price of the dataset?
The price is determined by your requirements. Please submit a request to get a free consultation.
DIDN'T FIND THE NECESSARY INFORMATION?
Leave a request for a free consultation and a test dataset!
Why
Training Data
- Quality Assurance:
-
Enhanced Data Accuracy
-
Consistency in Labels
-
Reliable Ground Truth
-
Mitigation of Annotation Biases
-
Cost and Time Efficiency
- Data Security and Confidentiality:
-
GDPR Compliance
-
Non-disclosure agreement
-
Data Encryption
-
Multiple data storage options
-
Access Controls and Authentication
- Expert Team:
-
6 years in industry
-
35 top project managers
-
40+ languages
-
100+ countries
-
250k+ assessors
- Flexible and Scalable Solutions:
-
24/7 availability of customer service
-
100% post payment
-
$550 minimum check
-
Variable Workload
-
Customized Solutions
