 Audio Transcription
Audio Transcription Datasets and Services for Training LLM
Datasets and Services for Training LLM Image Annotation
Image Annotation Video Annotation
Video Annotation Text Annotation
Text Annotation Lidar Annotation
Lidar Annotation Crowdsourcing
Crowdsourcing MedTech Companies
MedTech Companies Banking and Finance Industry
Banking and Finance Industry Biometric Data
Biometric Data E-commerce and Retail
E-commerce and Retail Surveys and UX-Researches
Surveys and UX-Researches Agriculture
Agriculture Retail
Retail Robotics
Robotics Augmented Reality
Augmented Reality Finance
Finance E-Commerce
E-Commerce Face Recognition System
Face Recognition System Ore Annotation
Ore Annotation Content Moderation on the Video
Content Moderation on the Video IBeta 2
IBeta 2 Data Collection for Face and Speech Recognition
Data Collection for Face and Speech Recognition Content Moderation
Content Moderation Video Systems and Video Analysis
Video Systems and Video Analysis Content Moderation in Recruitment Domain
Content Moderation in Recruitment Domain Audio Labeling for Call Center
Audio Labeling for Call Center Data collection and video annotation: weapon detection on the streets
Data collection and video annotation: weapon detection on the streets Image Annotation for Emotion Recognition
Image Annotation for Emotion Recognition Data Сollection for Сity Administration
Data Сollection for Сity Administration Liveness Detection
Liveness Detection Annotation Photos for the Recognition System
Annotation Photos for the Recognition System Blog
Blog Stages of Work
Stages of Work Become a Partner
Become a Partner Student Program
Student Program FAQ
FAQ
USE CASE
LLM Text Generation Dataset
Dataset with texts generated by LLM in 32 languages

NLP
The ability of a system to understand, analyze and interpret human's languages
LLM
Data to develop and fine-tune advanced language models capable of generating human-like text
Classification
Process of recognition and grouping of objects into preset categories
Data Collection
Gathering data for subsequent annotation
4 millions+
logs
3
models
32
languages
Our Partners








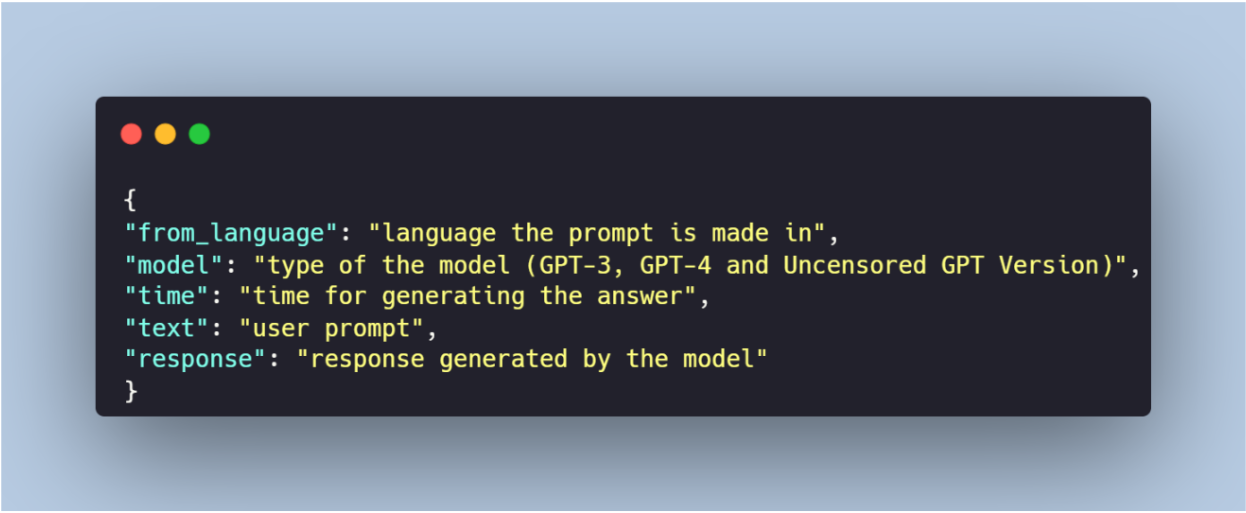
- Data provided by people all over the world: prompts and corresponding answers from LLMs
- 3 different types of GPT models: GPT-3.5, GPT-4 and Uncensored GPT
- Dataset includes prompts and texts in 32 languages

Meta for the dataset
Languages in the dataset
- Arabic
- Azerbaijani
- Catalan
- Chinese
- Czech
- German
- Greek
- English
- Esperanto
- Spanish
- Persian
- Finnish
- French
- Irish
- Hindi
- Hungarian
- Indonesian
- Italian
- Japanese
- Korean
- Malayalam
- Maratham
- Netherlands
- Polish
- Portuguese
- Portuguese (Brazil)
- Slovak
- Swedish
- Thai
- Turkish
- Ukrainian
THE FINAL COST OF THE PROJECT IS INFLUENCED BY
 Scope of work
Scope of work -
Markup complexity
-
Timing
-
Markup quality
Our data quality guarantee is 95%. When ordering markup with quality above 95%, we offer enterprise solutions
Request a quoteAPPLICATION AREAS OF THE DATASET
Language modeling and generation:
Data to improve language models and generation capabilities in natural language processing applications
Question answering systems:
The data to train question answering models that can provide accurate and relevant answers to user questions
Customer support automation:
LLM dataset to automate customer support responses, providing quick and accurate solutions to customer queries
Virtual assistants:
Dataset to train virtual assistants and improve their response accuracy and natural language processing capabilities
DIDN'T FIND THE NECESSARY INFORMATION?
Leave a request for a free consultation and a test dataset!
Why
Training Data
- Quality Assurance:
-
Enhanced Data Accuracy
-
Consistency in Labels
-
Reliable Ground Truth
-
Mitigation of Annotation Biases
-
Cost and Time Efficiency
- Data Security and Confidentiality:
-
GDPR Compliance
-
Non-disclosure agreement
-
Data Encryption
-
Multiple data storage options
-
Access Controls and Authentication
- Expert Team:
-
6 years in industry
-
35 top project managers
-
40+ languages
-
100+ countries
-
250k+ assessors
- Flexible and Scalable Solutions:
-
24/7 availability of customer service
-
100% post payment
-
$550 minimum check
-
Variable Workload
-
Customized Solutions
