 Audio Transcription
Audio Transcription Datasets and Services for Training LLM
Datasets and Services for Training LLM Image Annotation
Image Annotation Video Annotation
Video Annotation Text Annotation
Text Annotation Lidar Annotation
Lidar Annotation Crowdsourcing
Crowdsourcing MedTech Companies
MedTech Companies Banking and Finance Industry
Banking and Finance Industry Biometric Data
Biometric Data E-commerce and Retail
E-commerce and Retail Surveys and UX-Researches
Surveys and UX-Researches Agriculture
Agriculture Retail
Retail Robotics
Robotics Augmented Reality
Augmented Reality Finance
Finance E-Commerce
E-Commerce Face Recognition System
Face Recognition System Ore Annotation
Ore Annotation Content Moderation on the Video
Content Moderation on the Video IBeta 2
IBeta 2 Data Collection for Face and Speech Recognition
Data Collection for Face and Speech Recognition Content Moderation
Content Moderation Video Systems and Video Analysis
Video Systems and Video Analysis Content Moderation in Recruitment Domain
Content Moderation in Recruitment Domain Audio Labeling for Call Center
Audio Labeling for Call Center Data collection and video annotation: weapon detection on the streets
Data collection and video annotation: weapon detection on the streets Image Annotation for Emotion Recognition
Image Annotation for Emotion Recognition Data Сollection for Сity Administration
Data Сollection for Сity Administration Liveness Detection
Liveness Detection Annotation Photos for the Recognition System
Annotation Photos for the Recognition System Blog
Blog Stages of Work
Stages of Work Become a Partner
Become a Partner Student Program
Student Program FAQ
FAQData Annotation Types: The Complete Guide
In this complete guide, you’ll learn about the different types of data annotation and how to implement them. We’ll cover everything from basic labeling to semantic segmentation so you can get your datasets ready for primetime.
With the right annotations, your models will start cranking out predictions like a well-oiled machine. Let’s dive in and shed some light on this critical but often overlooked step in the machine learning pipeline. You’ll be annotating like a pro in no time.
What Is Data Annotation?
Data annotation refers to the process of adding informative labels, descriptions or tags to raw data to provide context and meaning. In short, annotating data helps turn it into useful information that can then be leveraged for various purposes like training AI models or improving search relevance.
Types of Annotation
There are several types of data annotation depending on the end goal. The three most common are:
- Structural annotation: Adding labels to content to define its structure, like paragraphs, sentences, headings, etc. This helps with tasks like text summarization or sentence boundary detection.
- Semantic annotation: Adding labels to define the meaning of content, such as entities (people, places, organizations), relationships, sentiments, etc. This is useful for natural language understanding and chatbots.
- Image annotation: Adding labels, bounding boxes, and descriptions to images and videos. This enables computer vision applications like facial recognition, self-driving cars, and automated tagging of visual content.
The Annotation Process
The annotation process typically involves three main steps:
- Selecting the data to annotate: This could be text, images, audio, video or a combination. The data is usually raw and unstructured.
- Choosing an annotation technique: The most common techniques are manual annotation by human annotators, automated annotation using AI and machine learning models, or a hybrid of manual and automated annotation.
- Applying annotations: Annotators review the data and apply labels, tags or descriptions as per the project guidelines. Quality checks are done to ensure high accuracy and consistency.
Data annotation requires time and effort but produces high-quality datasets that fuel AI innovation. With a clear understanding of the different types and steps involved, you can determine if data annotation is right for your project.
Why Is Data Annotation Important?
Data annotation is crucial for training AI systems and improving machine learning models.###Enables Machine Learning
Without data annotation, machine learning models would have no way of learning how to identify and classify data. Teams of human annotators go through large datasets and manually label images, text, audio, and video to help train machine learning algorithms.
Improves Model Accuracy
The more high-quality training data fed into an ML model, the more accurate it can become. Data annotation helps ensure machine learning models make the right predictions and decisions. Models trained on annotated datasets tend to make fewer errors and have higher precision.
Saves Time and Money
While data annotation does require an upfront investment of resources, it pays off in the long run. Properly annotated data can help machine learning models reach high accuracy levels faster, reducing the need for constant re-training and tweaking. It also minimizes the errors and poor performance that would result from low-quality data, saving time spent fixing issues.
Enables New Insights
Looking at data with a critical human eye during the annotation process can lead to new insights that machines may miss on their own. Annotators analyze the meaning, relationships, and context within data, identifying subtle patterns and details that algorithms struggle to detect. These insights fuel discoveries and help teams better understand their data.
Adapts to Changing Needs
The data annotation process is flexible and adaptable. As machine learning models evolve and new use cases emerge, annotation techniques and guidelines can be adjusted to suit new needs. Annotated datasets created for one purpose today may be re-used and built upon for entirely different applications in the future. Data annotation helps ensure that training data remains relevant and useful over time.
Types of Data Annotation
Manual Annotation
Manual annotation involves human annotators labeling and categorizing data by hand. While time-consuming, manual annotation often produces high-quality training data. There are a few types of manual annotation:
Crowdsourcing
Crowdsourcing taps into the collective intelligence of a large group of people to annotate data. Platforms like Amazon Mechanical Turk allow you to distribute annotation tasks to many workers. Crowdsourcing is a quick and affordable way to generate large annotated datasets. However, quality control can be an issue, so data validation is important.
Expert Annotators
Hiring expert annotators with domain expertise produces very high-quality data but at a higher cost. Expert annotators go through extensive training to ensure consistency and accuracy. This approach is best for complex annotation tasks.
In-House Annotators
Some companies train in-house annotators to label their proprietary data. In-house teams allow for tight quality control and consistency but require significant time and money to set up. In-house annotation is a good option if data privacy and security are a concern.
Automated Annotation
Automated or semi-automated annotation uses machine learning algorithms to annotate data. Automated methods are faster and often cheaper than manual annotation. However, for complex annotation tasks, the accuracy and quality of machine-generated labels may not match human annotators. There are a few types of automated annotation:
Rule-Based Annotation
Rule-based systems use handcrafted rules to annotate data. This approach requires extensive domain expertise to define effective rules but can work well for some simple annotation tasks.
Active Learning
Active learning methods analyze unlabeled data to identify which samples would be most valuable for humans to annotate. The models can then query humans to annotate specific samples, using the new labeled data to retrain models and continue improving. Active learning reduces the total amount of annotation required.
Machine Learning
Machine learning models can be trained on partially annotated datasets to predict labels for new data. The performance of machine learning methods depends heavily on the quality and quantity of training data. Machine learning tends to work best when combined with human annotators in an active learning framework.
Image Annotation
Image annotation is the process of labeling images to detect objects, scenes, concepts or attributes. It involves drawing bounding boxes around objects or regions of interest in images and providing textual descriptions of those areas.
Object Detection
Object detection aims to locate and classify objects in images and videos. You annotate images by drawing bounding boxes around objects and labeling them with the object class. This helps train machine learning models to detect specific objects like cars, people or trees.
Image Segmentation
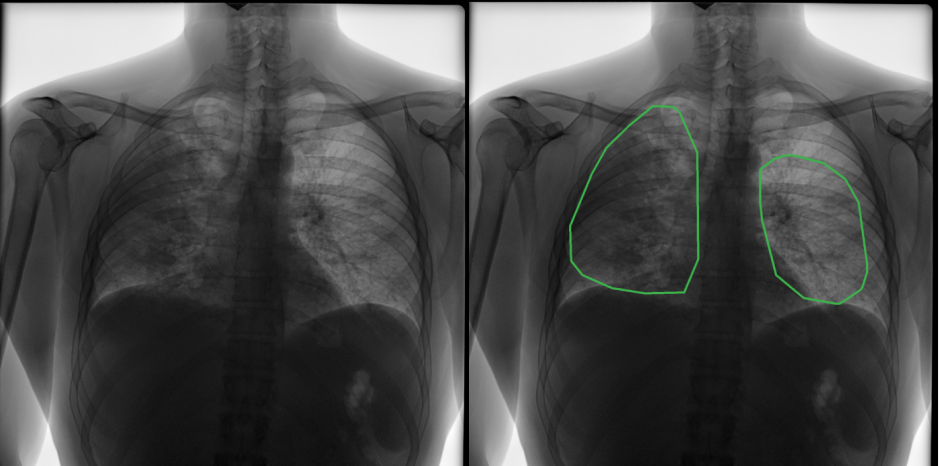
Image segmentation goes a step further by annotating at the pixel level. You label groups of pixels that belong to the same object or region. This allows machine learning models to gain a more granular understanding of images by segmenting them into finer component parts. Image segmentation is useful for applications like medical imaging, self-driving cars and satellite imagery analysis.
Scene Classification
With scene classification, you annotate images by labeling them with scene categories like ‘city street’, ‘forest’ or ‘beach’. This trains models to classify new images into the correct scene category. Scene classification powers applications such as intelligent photo categorization and content-based image retrieval.
Attribute Detection
Attribute detection focuses on annotating attributes of objects or scenes like ‘red’, ‘round’ or ‘crowded’. You label images with the attributes that apply to them. This enables machine learning models to detect attributes in new images.
Attribute detection is useful for applications such as fashion analysis, facial attribute analysis and visual question answering.
Image annotation may require domain expertise and can be time-consuming, but it is crucial for training high-performance computer vision models. With high-quality annotated data, machine learning algorithms can gain a deeper understanding of images and power intelligent applications.
Text Annotation
Text annotation involves highlighting specific words, phrases or passages in a text and adding notes to provide context or analysis. This helps identify key terms, summarize main ideas or capture insights.

Manual Annotation
The most common approach is manual annotation where human annotators read through texts and annotate them based on guidelines. This requires annotators with subject matter expertise and can be time-consuming for large data sets. However, it often produces high-quality annotations.
Some tips for manual text annotation:
- Develop clear annotation guidelines to ensure consistency across annotators. Define what should be annotated and how.
- Provide annotators with examples to help them understand the guidelines.
- Have multiple annotators annotate the same texts independently and measure inter-annotator agreement to check for consistency. Discrepancies will need to be resolved through discussion.
- Consider using annotation tools like Doccano or INCEpTION which provide interfaces to simplify the annotation process.
- For more complex annotations, break down the task into multiple stages. For example, annotate entities first before relations.
- Monitor progress and review annotations regularly to provide feedback to annotators.
- Consider crowd-sourcing annotations to scale the process. But pay close attention to quality control.
Automatic Annotation
Automatic text annotation uses machine learning algorithms to annotate data. This is often used when scale and speed are priorities. However, the quality may be lower than human annotation.
Some common approaches for automatic text annotation include:
- Rule-based annotation which uses pattern matching rules to identify annotations. This requires developing robust rules which can be challenging.
- Supervised machine learning models trained on manually annotated data. Performance depends on the size and quality of training data. Models need to be retrained when new data is added.
- Active learning models which start with a small set of manually annotated data and ask annotators to label examples the model is most uncertain about. This iterative process expands training data efficiently.
- Transfer learning which leverages annotations from related data sets to bootstrap a new model. Fine-tuning on a small in-domain data set can help adapt the model.
- Unsupervised models which cluster similar words or passages together without manual labels. Clusters can then be manually reviewed and labeled.
In the end, a combination of manual and automatic annotation often works best to maximize benefits and minimize drawbacks. The key is finding the right balance for your project.
Video Annotation
Video annotation involves tagging videos with metadata that describes the content. This could include descriptions of scenes, identification of objects, people or events, or classification of the video topic.
With the rise of video platforms and streaming services, video annotation has become crucial for searchability and recommendation engines.
Scene and Object Annotation
Scene and object annotation involves identifying objects, locations, activities, concepts or events within a video. For example, you may tag a beach scene with metadata like “ocean”, “sand”, “people swimming”. Or identify objects like “palm tree”, “surfboard”, “seagull”. This helps video search engines understand the content and themes of the video.
Person Annotation
For videos featuring people, you can annotate individuals by tagging their names, roles or other attributes. For example, in an interview video you may tag “John Smith” as the “interviewee” and “Jane Doe” as the “interviewer”. Or for a movie, tag actors’ names and the characters they play. Person annotation allows viewers to search for specific individuals within a video collection.
Topic Classification
Topic classification involves assigning categories or themes to describe a video’s overall subject matter. For a video about how to change a tire, you may assign the topic “automotive repair”. For a nature documentary, you could use “environment” or “biology”.
Topic metadata helps video platforms categorize and recommend related videos to viewers based on their interests.
Sentiment Analysis
For some videos, it can be useful to analyze the overall sentiment or opinions expressed. You can tag a video as expressing a “positive”, “negative” or “neutral” sentiment. For a product review video, sentiment analysis would help viewers find videos with opinions they are most interested in. Sentiment metadata may also help video platforms avoid recommending videos with overly negative or distressing sentiments.
Video annotation requires human judgment and an understanding of the video’s visual content and audio narration or dialog. While automation and AI are improving, human video annotators still provide the most accurate and comprehensive metadata tagging and analysis. The end result is an enriched video experience for viewers and more powerful search and recommendation capabilities for video platforms.
Audio Annotation
Transcription
Transcribing audio data involves converting speech into text. This is commonly done to generate transcripts of audio files like podcasts, interviews, speeches, and lectures. As an annotator, your task would be to listen to audio clips and type out exactly what is being said, including punctuation, to create an accurate written record of the audio.
Transcription requires close listening skills, quick and accurate typing abilities, and knowledge of punctuation, grammar and spelling. It can be challenging to keep up with fast speech and transcribe every word correctly. You may need to play sections multiple times. Transcription is a useful annotation type, especially for researchers working with speech data or looking to create datasets for training speech recognition models.

Sentiment Analysis
With sentiment analysis, you analyze audio clips to determine the emotional tone and opinions expressed. Are the speakers expressing positive, negative or neutral sentiments? As an annotator, you need to listen for emotional cues like tone of voice, intensity, and word choice to make an assessment.
Sentiment analysis of audio data is useful for companies looking to gauge customer reactions and opinions or for social scientists researching emotional expression.
Topic Classification
Topic classification involves listening to an audio clip and determining the main subject or theme. You assign one or more labels to indicate what the content is about, like business, politics, technology or entertainment.
Researchers can then analyze patterns in the topics that people discuss. As an annotator, you need to fully understand the clip to choose accurate topic labels. Multiple annotators may be needed to reach high agreement.
Speaker Diarization
With speaker diarization, the goal is to determine “who spoke when.” As an annotator, you listen to a conversation between multiple speakers and label each line with the speaker’s identity. This allows researchers to analyze patterns in how different people interact and participate in discussions.
Performing speaker diarization requires close listening to recognize different voices and follow the flow of a multi-speaker conversation. It can be challenging, especially when speakers have similar voices or when audio quality is poor.
How to Choose the Right Annotation Type
With so many annotation types to choose from, how do you determine which is right for your project? The answer depends on your data, goals, and resources.
Data Characteristics
Consider what types of data you have and what information you want to capture from it. For image data, you’ll want to use image annotation. For text, choose text annotation. For audio, opt for audio transcription or annotation. Think about the level of detail needed – you’ll need finer-grained annotation for complex data.
Project Goals
Think about how the annotated data will be used. Do you need annotations for machine learning and AI? Choose a type that will generate the specific data needed to train your models. For search relevance or data filtering, simpler annotation may suffice. For creating knowledge bases, you’ll want semantic annotation.
Available Resources
Some annotation types require more time, money, and human effort. If resources are limited, choose a simpler method. Automated or semi-automated tools can help reduce costs for some types of annotation. Consider your budget and timeline, as well as the availability of human annotators with relevant subject-matter expertise.
In the end, the right annotation approach for your project depends on balancing these factors. Don’t underestimate the time and effort required for high-quality human annotation – it is still the gold standard for creating training data. If done well, data annotation provides the fuel to power today’s data-hungry machine learning systems. With the proper strategy and investment, it can enable transformative AI and a competitive advantage.
FAQs About Data Annotation Types
Do I need to annotate all my data?
Not necessarily. You only need to annotate the data that will be used for training your ML models. Any data used for testing the models does not need to be annotated.
How much data should I annotate?
The amount of data you need to annotate depends on several factors:
• The complexity of your ML task – More complex tasks like image segmentation require more annotated data than simple classification tasks.
• The size of your dataset – If you have a very large dataset, annotating all of it may be impractical. In that case, annotate a representative sample.
• Your team’s annotation bandwidth – Consider how many annotations your team can do in a given time period and budget accordingly.
• Data imbalance – Make sure you annotate enough examples of under-represented classes to avoid skewed models.
• Desired model accuracy – Higher accuracy models typically require more annotated data.
In general, for many simple ML tasks, annotating a few thousand examples is enough to get started. You can then evaluate your model and annotate more data if needed.
What are some tips for managing an annotation project?
Here are some helpful tips for managing a data annotation project:
- Clearly define your annotation guidelines and provide examples. This will ensure consistency across annotators.
- Split your dataset into batches and re-annotate a portion of each batch to track annotator agreement and catch issues early on.
- Provide continuous feedback and training for your annotators. Review any disagreements and clarify guidelines as needed.
- Consider using annotation software to streamline the process. Many tools offer useful features like customized interfaces, annotation workflows, and project management.
- Check in on your annotators regularly to answer any questions and make sure the work is progressing as expected.
- Once annotation is complete, evaluate a portion of the work to ensure high quality before using the data to train your models.
- Keep records of your annotation procedures and guidelines for future reference. This will save time if you need to re-annotate or expand the dataset.
Does data annotation really make a difference?
Yes, annotated data is essential for training high-quality machine learning models. ML models rely on large amounts of high-quality training data to learn how to perform tasks accurately. Annotated data provides the labels or targets needed for supervised learning. Without annotated data, most ML models would not function.
Conclusion
So there you have it – a complete guide to the main data annotation types. Whether it’s text, image, video, or audio data, understanding the different annotation methods is key to creating quality training data. We covered the basics of classification, bounding boxes, segmentation, transcriptions, and more. Putting this knowledge into practice takes time and experience. Start small, learn from your mistakes, and lean on your team’s expertise. With the right annotations, your models will continue to improve. But don’t stop here!
Stay on top of new techniques and keep pushing yourself. The world of data annotation is evolving rapidly. Stick with it, trust the process, and you’ll be building better AI systems in no time. Now go annotate some data!
