 Audio Transcription
Audio Transcription Datasets and Services for Training LLM
Datasets and Services for Training LLM Image Annotation
Image Annotation Video Annotation
Video Annotation Text Annotation
Text Annotation Lidar Annotation
Lidar Annotation Crowdsourcing
Crowdsourcing MedTech Companies
MedTech Companies Banking and Finance Industry
Banking and Finance Industry Biometric Data
Biometric Data E-commerce and Retail
E-commerce and Retail Surveys and UX-Researches
Surveys and UX-Researches Agriculture
Agriculture Retail
Retail Robotics
Robotics Augmented Reality
Augmented Reality Finance
Finance E-Commerce
E-Commerce Face Recognition System
Face Recognition System Ore Annotation
Ore Annotation Content Moderation on the Video
Content Moderation on the Video IBeta 2
IBeta 2 Data Collection for Face and Speech Recognition
Data Collection for Face and Speech Recognition Content Moderation
Content Moderation Video Systems and Video Analysis
Video Systems and Video Analysis Content Moderation in Recruitment Domain
Content Moderation in Recruitment Domain Audio Labeling for Call Center
Audio Labeling for Call Center Data collection and video annotation: weapon detection on the streets
Data collection and video annotation: weapon detection on the streets Image Annotation for Emotion Recognition
Image Annotation for Emotion Recognition Data Сollection for Сity Administration
Data Сollection for Сity Administration Liveness Detection
Liveness Detection Annotation Photos for the Recognition System
Annotation Photos for the Recognition System Blog
Blog Stages of Work
Stages of Work Become a Partner
Become a Partner Student Program
Student Program FAQ
FAQSegmentation and Tracking Case: Ore Annotation for a Mining Company
Data annotation is a well-established niche in technical fields, serving as the foundation for training neural networks. In recent months, everyone has been discussing LLM and data generation, but at the same time, artificial intelligence technologies are actively advancing in the industrial sector.
My name is Alexey Kornilov, and I am a project manager for data collection and annotation at Training Data. I want to talk about how data collection and annotation are used by ML developers in a mining company. About a year ago, I completed a project to prepare datasets with bubble annotation during flotation. It may sound complicated, but let’s break it down step by step.
The ultimate goal of the project was to train a neural network to control and analyze one of the stages of ore concentrate production at the plant. In other words, it was a task aimed at automating and mechanizing manual labor in potentially hazardous conditions for humans.
I want to focus on the stages and specifics of such data annotation, the organization of the annotation team/AI trainers, and share insights into working with industrial data. This article will be of interest to project managers, data scientists, ML engineers, and anyone working in data annotation for machine learning tasks.
Task definition and specification
To train a neural network, we needed data with two types of annotations: semantic segmentation and tracking. Often, we parse or collect data for annotation, but when it comes to heavy industry, data is provided to us along with a technical specification.
The photos show frames from surveillance cameras located above flotation machines. The images display the flows of numerous bubbles, the sizes and quantities of which indicate the readiness of the ore for the next processing stages. Below is an example of data for annotation. Three streams of bubble movement in the reservoir are highlighted with color:
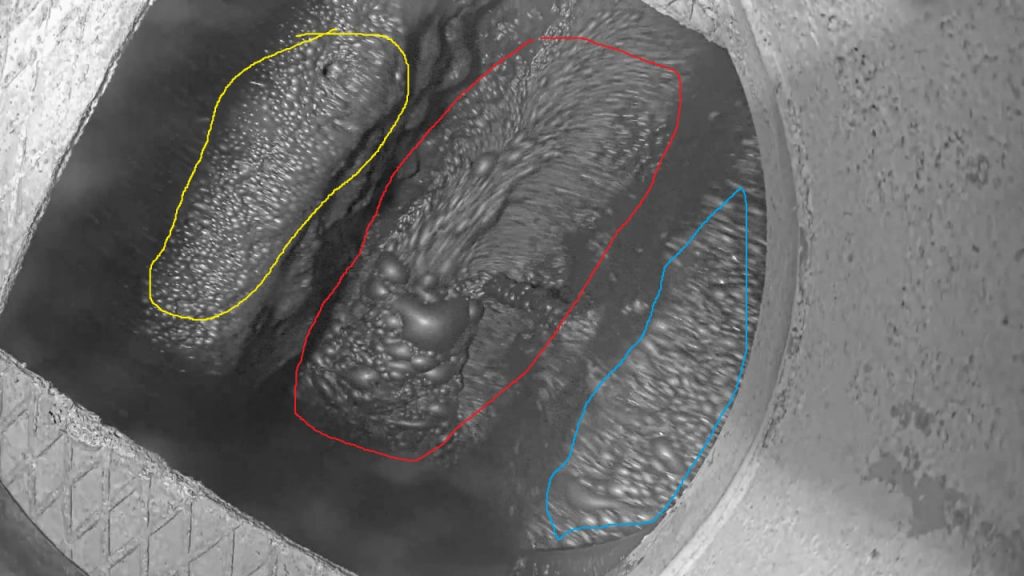
At first glance, the task may seem daunting because not only do we need to annotate each bubble, but we also need to assign a unique ID to each one and ensure we don’t lose track of them in subsequent frames.
But in reality, for AI trainers, it doesn’t matter what needs to be annotated. From a technical standpoint, all segmentation tasks are the same, whether you’re working with people, vegetables, or bubbles. However, this project had its own unique features and complexities that became apparent during the pilot phase (a pilot is a test project to determine metrics and refine the project’s specifications).
So, according to the pilot project’s specifications, we performed two types of tasks:
1. Semantic Segmentation: Outlining the contours of each bubble with polygons to determine the characteristics of the bubble foam.
2. Object Tracking: Annotating each bubble with a bounding box, assigning a unique ID to each box, and tracking the position of the ID for each bubble across all subsequent frames.
The Pilot Project: Initial Challenges
Despite having a well-written specification, no project can exist without corner cases. In this case, we encountered a complex life cycle of bubbles. A bubble forms, grows, transforms, explodes, and disappears, leaving only its shape behind. In the photos, it looks like a lunar crater. During the pilot project and for creating a reference annotation to guide our project delivery, it was crucial to make as many clarifications as possible. In this case, we asked our client following questions:
- How to annotate the moment of a bubble’s explosion?
- How to annotate the shape without the bubble?
- What is the minimum size for a bubble to be annotated? What qualifies as a “small” bubble?
High-quality data accounts for 80% of the neural network’s correct functioning, so we always carefully study the instructions, ask questions, and deliver the annotations in iterations to ensure that developers achieve the desired and predictable results. You could say we work according to the Agile methodology, which is a flexible approach to project management.
Bubbles, Graphics Cards, and Colors: Project Specifics
The second peculiarity of the data was the number of bubbles. You might have already asked yourself how many bubbles need to be annotated in one image. Before answering that question, let me give you two interesting examples that vividly illustrate the situation:
1. One of the AI trainers on my team worked so diligently that at one point, he noticed glitched pixels on his screen. Yes, his graphics card burned out during image annotation. To preemptively address questions, it was an NVIDIA GeForce 3060 Ti. Fortunately, everything turned out fine because he had a warranty.
2. We wrote code to assign a unique color to each bubble. By default, we set a limit of 1000 colors. However, on the second data export, the script stopped working. Yes, it was because of the limitation, as the number of bubbles in one photo ranged from 2 to 1500.

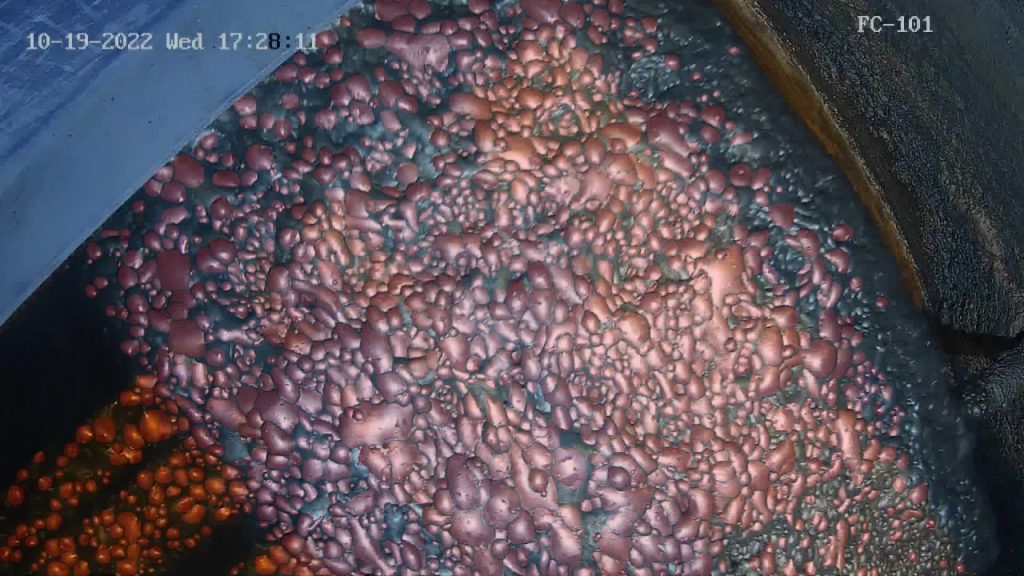
At first glance, the task may seem daunting because not only do we need to annotate each bubble, but we also need to assign a unique ID to each one and ensure we don’t lose track of them in subsequent frames.
But in reality, for AI trainers, it doesn’t matter what needs to be annotated. From a technical standpoint, all segmentation tasks are the same, whether you’re working with people, vegetables, or bubbles. However, this project had its own unique features and complexities that became apparent during the pilot phase (a pilot is a test project to determine metrics and refine the project’s specifications).
So, according to the pilot project’s specifications, we performed two types of tasks:
1. Semantic Segmentation: Outlining the contours of each bubble with polygons to determine the characteristics of the bubble foam.
2. Object Tracking: Annotating each bubble with a bounding box, assigning a unique ID to each box, and tracking the position of the ID for each bubble across all subsequent frames.
Team: Three Key Qualities
With the project launch, the process of working with the team began: training, data distribution, metric setting, quality control, and psychological support, which includes dealing with fatigue.
Among all the annotation tools available, in most cases, we use CVAT, unless the client or the task type suggests otherwise. First and foremost, I trained the team to annotate bubbles specifically, showed them the hotkeys and ways to optimize their time for this project. However, for obvious reasons, this project quickly became one of the least favorite among the annotators.
Different projects come into the company, and not all of the 2500 annotators possess the full range of skills needed for bubble annotation. Over time, I was able to clearly formulate the skills and qualities required for such projects:
1. Proficiency in CVAT: Despite all the training and instructions, someone without significant experience in computer vision annotation tools would not achieve the required speed and quality metrics.
2. Patience and Attention to Detail: This forms the basis for meticulous annotation. When you have 1500 objects in 50 shades of gray in front of you, you need to pay attention to each pixel. Sometimes, it can take 2-3 hours for a single image, which is not easy on a project spanning several months.
3. Self-regulation: This is about taking breaks and mindfulness. There’s a fine line between being focused and having tired eyes. In our team, we established a rule that everyone should make a fresh cup of tea and stretch every 4 hours.
For the manager, this project required not only persistence but also understanding and attention to the team’s needs.
Optimization and Neural Networks
Today, at Training Data, there is an innovation department responsible for developing new scripts, testing platforms and tools, implementing neural networks, configuring pre-labeling, and providing other technical support to ensure teams work comfortably. At the time of the described project, this department did not exist, but automation was already in place.
We previously mentioned a script that assigns a unique color to each ID. After realizing that there could be more than 1000 bubbles in an image, we increased the limit to 2000 colors, which was difficult to exceed.

The second solution was related to images containing between 500 and 1500 bubbles. We divided each frame into 4 quadrants, drew a cross to preserve boundaries, annotated each part separately, and then stitched them back together into one image, adjusting the annotations at the seams if necessary. Testing showed that this saved up to 8 hours of annotation time! At the time, I felt like I had come up with a brilliant solution, as we had never done this before.
Could a neural network annotate this type of image? Yes, but the question of quality arises. The raw data consists of frames from a video in which bubbles move at high speed. When zoomed in, everything is very pixelated, and the neural network likely wouldn’t be able to determine object boundaries due to pixelation.

What did we learn during this project?
This case allowed us to draw several interesting conclusions:
- The number of bubbles turned out to be an unexpected challenge. Working with images placed a significant load on the annotators’ computers. The experience in annotating with CVAT and the technical specifications of the annotators’ computers limited the pool of specialists eligible to work on the project. Now, when forming teams for a project, we always inquire about the annotators’ computers and graphics cards.
- It also turned out that women performed better in annotating bubbles. They displayed greater patience, completed batches of annotations to the end, and took a more responsible approach to their work in general. Often, male annotators lacked the patience to work on small bubbles, and sometimes they abandoned the task halfway, something that the female annotators never did. This is likely related to their overall resilience to stress and their ability to work with details.
